Foreword
Hey, Francisco

As promised: here is a description of what I implemented. With you as the primary audience, I decided to write it in English.
The Situation
We have a maven-project with lots of sub-modules. We like to call it "Klotz" (German for chunk)!
There is a VCS (namely mercurial) and all the development happens in the branch "default".
Every now and then a release-branch is created from the current default-status.
The version in the default-branch is updated once a year, and for the release-branches the versions are changed as follows:
find -name pom.xml -exec sed -i "s/19.0.0-SNAPSHOT/19.2.2.0-SNAPSHOT/g" {} \;
The Issues
- The default-branch is unstable from time to time, as every developer commits its work-in-progress to this branch.
- Working with branches in mercurial is a pain, especially as branches are global - so feature-branches are rarely used. (The bookmark-extension might be good enough for local work, but its not an adequate replacement)
- Bug-fixes are committed directly into the release-branch - without changing its version. So the version that's deployed on production might not be what you expect.
The Target
It is 2019! So it should be possible to do better!
We want:
- a cleaner branching-model and workflow.
- creating releases, hot-fixes and updating versions with the press of a button
- enforce working with pull-requests
The Challenges
Due to the combination of maven and git(flow) several challenges arise.
The first being: having your code in well defined branches will not automatically update your versions in the pom.xml files. So we need a tool for that.
The second is: having different versions/pom.xml in the different branches makes merging quite difficult. So we need tool-support for this as well.
The third challenge is due to the deployment-process we have. The application is deployed based on the maven-artifacts in the company repository, and not the code itself.
So if you want to deploy the changes in a feature-branch, the version in the pom.xml files in this branch must be changed accordingly. But doing so prevents you from creating a simple Pull-Request from this feature-branch to development-branch. So - you guess it - we need tool-support for this case as well.
And speaking of Pull-Requests: of course the developers need to keep in mind the different versions in the branches when creating them. A PR from a branch based on a hotfix-branch against the development-branch for example might not be a good idea.
Implementing a Solution
The Tools...
As mentioned above, we need tool-support, and luckily there is one:
gitflow-maven-plugin
The official repo/version still contains some bugs/short-comings. I created a fork with corresponding changes and fixes - hopefully they get merged upstream soon:
https://github.com/Iridias/gitflow-maven-plugin/tree/current-status
Whats different:
- pull dev-branch before pushing to avoid rejection due to remote-changes
- support the option to not merge the release-branch into dev-branch
- support processAllModules of versions-maven-plugin (important for child-modules without parent specified)
- support separate additional merge-options on hotfix-finish and release-finish, for merging into production-branch and dev-branch respectively
With this plugin at hand, we're prepared to face the first requirement.
The "release with a press of a button"-requirement can be solved with
JenkinsCI. If you're not using Jenkins, your alternative should provide similar capabilities for configuring freestyle-jobs. If not: why are you using it anyway?
To enforce the usage of pull-requests, we make use of the branching-restrictions of Bitbucket - because we already have Bitbucket available. But other alternatives, e.g. gitlab, rhodecode or azure devops have similar features - at least in the paid versions.
Now that we have our tools together...
Lets start!
Migration
First we need to setup the git-repository.
To
migrate the mercurial-repository to git, we use
https://github.com/frej/fast-export
Then we need a development-branch:
git branch development
And finally we add the Bitbucket repository as remote and push everything:
git remote add origin ssh://user@yourgitrepo/project.git
git push -u origin --all
Permissions
Now that the project is in the new git-repository, we can configure the branch-permissions:
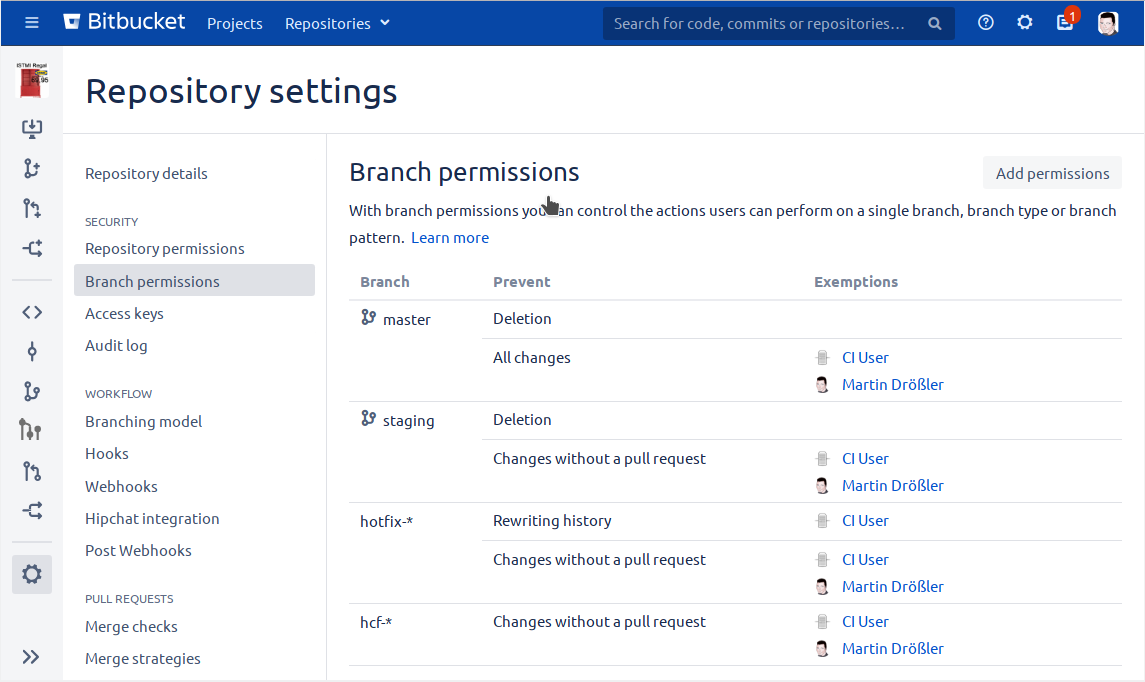
..as well as the merge-checks:
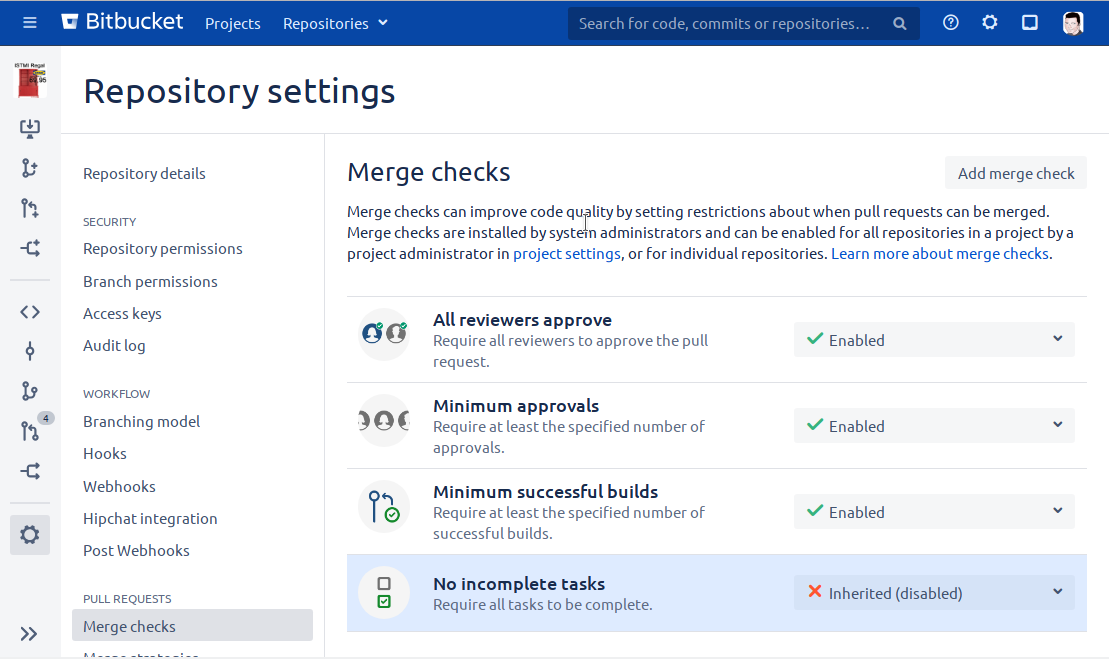
As you can see, we need an account for an
ci-user. Because someone has to have the right to merge the changes into the corresponding branches, when using the
gitflow-maven-plugin.
And maybe you, as admin, want to have such permissions too - in order to fix things that might go wrong.
Jenkins Jobs
For the next step, we need several Jenkins-Jobs.
To verify the application itself, we need jobs for building Pull-Request and the various branches:
- Build-PR
- Build-Develop
- Build-Master
- Build-Hotfix
- Build-Feature
- Build-Release
Next we need jobs to invoke the gitflow-maven-plugin:
- Version-Create-Feature-Branch
- Version-Finish-Feature-Branch
- Version-Create-Hotfix-Branch
- Version-Finish-Hotfix-Branch
- Version-Create-Release-Branch
- Version-Finish-Release-Branch
For the "Build-PR" Job, you'll need to use the
bitbucket-pullrequest-builder-plugin (
https://github.com/nishio-dens/bitbucket-pullrequest-builder-plugin) if you're using
Bitbucket-Server!
This is due to a
bug in Bitbucket-Server, that won't send/trigger a web-hook when a pull-request is updated:
https://jira.atlassian.com/browse/BSERV-10279
For the following Jobs, you must use wildcards in the branch-specifier of the jenkins-git-plugin:
- Build-Hotfix
- Build-Feature
- Build-Release
That's due to the fact, that the corresponding branches always have the same prefix, but the actual name differs and can't be known beforehand.
It's not a big deal, as it can be specified like follows:
*/hotfix-*
But the important thing is, that you
must not delete the workspace after the build (Post-Build action)! You can, on the other hand, delete it before build!
That's because Jenkins can't check for changes in the matching branches without the project being checked out in the workspace!
Deploy the maven artifacts
As we're using
Sonatype Nexus Repository for our maven repository, I decided to also introduce
nexus-staging-maven-plugin.
It replaces the default deploy-maven-plugin and makes the process more robust, as it ensures, that
all artifacts are deployed or none.
So if something horrible happens during the upload-process, you won't end up with an inconsistent state.
The downside is: to have that feature also for release-artifacts (and not just snapshots) you'll need the paid professional version of Nexus Repository.
Use
-DskipStaging=true as parameter for
mvn deploy in the job that creates your release-artifacts - otherwise the build will break.
But, well, it's an improvement anyway, so it might be worth considering it.
The Jenkins-Jobs in detail:
Version-Create-Feature-Branch
Parameter:
Type:
Text
Name:
FeatureName
Shell Build-Step:
echo "Checking Feature-Name...";
if [[ ! "${FeatureName}" =~ ^[a-zA-Z0-9_\-]*$ ]]; then
echo "Invalid Feature-Name specified! Aborting!";
exit 1;
fi
echo "Fetching repository...";
git clone ssh://USER@yourgitrepo:9999/prj/repo-name.git
cd repo-name
# gitflow:feature-start checks for existing branch in refs/heads/ instead of refs/remotes/origin
git branch -r | grep -v '\->' | grep -v 'master' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git pull --all
git checkout staging
echo "Starting feature-branch...";
mvn -U -B gitflow:feature-start -DversionProcessAllModules=true -DinstallProject=false -DskipFeatureVersion=false -DallowSnapshots=true -DpushRemote=true -DfeatureName="${FeatureName}"
We're doing the git clone in the shell-script, because we have to do some additional git operations. If we'd use Jenkins' git-plugin, this would lead to an error like:
fatal: could not read Username for 'https://yourgitrepo'
As stated in the comment, the loop to create local tracking-branches is necessary, due to how the gitflow-plugin works. This applies to the following jobs as well - but I won't mention it again.
Version-Finish-Feature-Branch
Parameter:
Type:
Extensible Choice
Name:
FeatureName
Groovy Script:
def p = "/path/to/fetch-feature-branches.sh".execute()
p.waitFor()
File versions = new File("/path/to/git-feature-branch-names.txt")
return versions.readLines()
fetch-feature-branches.sh:
#!/bin/bash
cd /path/to/copy/of/your/repo-name
git pull --rebase --all
git remote prune origin
# dfb == deployable feature branch
git branch -r | grep "dfb-" | sed -e 's/.*dfb-//gi' > /path/to/git-feature-branch-names.txt
Shell Build-Step:
echo "Checking Feature-Name...";
if [[ ! "${FeatureName}" =~ ^[a-zA-Z0-9_\-]*$ || -z "${FeatureName}" ]]; then
echo "Invalid Feature-Name specified! Aborting!";
exit 1;
fi
echo "Fetching repository...";
git clone ssh://USER@yourgitrepo:9999/prj/repo-name.git
cd repo-name
git branch -r | grep -v '\->' | grep -v 'master' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git pull --all
echo "Finish feature-branch...";
mvn -U -B gitflow:feature-finish -DversionProcessAllModules=true -DinstallProject=false -DadditionalMergeOptions="-Xours" -DskipTestProject=true -DskipFeatureVersion=false -DallowSnapshots=true -DpushRemote=true -DfeatureName="${FeatureName}"
FIXME: merge-options need to be adapted according to Version-Finish-Hotfix-Branch
The Extensible Choice plugin and the script to fetch the existing feature-branches is not required - but its definitely more convenient for your users!
They can simply select the right feature-branch instead of determining the name them-self and struggle with typos - and trust me: they're
always struggling with typos!
Version-Create-Hotfix-Branch
Shell Build-Step:
echo "Fetching repository...";
git clone ssh://USER@yourgitrepo:9999/prj/repo-name.git
cd repo-name
git branch -r | grep -v '\->' | grep -v 'master' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git pull --all
echo "check for existing hotfix-branch..."
amount=`git branch -r |grep -i "hotfix-" | wc -l`
if [ $amount -gt 0 ]; then
echo "Found $amount existing hotfix-branche(s)! Aborting...";
exit 2;
fi
echo "creating hotfix branch..."
mvn -B gitflow:hotfix-start -DversionProcessAllModules=true -DuseSnapshotInHotfix=true
git push -u origin --all
Exit code to set build unstable:
2
Maybe you want to also use the Slack Notification Plugin.
There shall be only one hotfix-branch at a time - so no parameters needed.
Version-Finish-Hotfix-Branch
Parameter:
Type:
Select
Name:
MergeStrategy
Values:
AUTO
HOTFIX
STAGING
MANUAL
Shell Build-Step:
echo "Fetching repository...";
git clone ssh://USER@yourgitrepo:9999/prj/repo-name.git
cd repo-name
git branch -r | grep -v '\->' | grep -v 'master' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git pull --all
echo "check for existing hotfix-branch..."
amount=`git branch -r |grep -i "hotfix-" | wc -l`
if [ $amount -eq 0 ]; then
echo "No existing hotfix-branch found! Aborting...";
exit 2;
fi
hotfixBranchVersion=`git branch -r |grep -i "hotfix-" | sed -e 's/.*hotfix-//gi'`
skipMergeDevBranch="false"
keepHotfixBranch="false"
devBranchMergeOptions="";
if [ "${MergeStrategy}" == "HOTFIX" ]; then
devBranchMergeOptions="-Xtheirs";
elif [ "${MergeStrategy}" == "STAGING" ]; then
devBranchMergeOptions="-Xours";
elif [ "${MergeStrategy}" == "MANUAL" ]; then
skipMergeDevBranch="true";
keepHotfixBranch="true";
fi
echo "releasing hotfix branch..."
mvn -U -B gitflow:hotfix-finish -DversionProcessAllModules=true -DskipTestProject=true -DallowSnapshots=true -DuseSnapshotInHotfix=true -DproductionBranchMergeOptions="-Xtheirs" -DdevBranchMergeOptions="${devBranchMergeOptions}" -DkeepBranch="${keepHotfixBranch}" -DskipMergeDevBranch="${skipMergeDevBranch}" -DhotfixVersion="${hotfixBranchVersion}"
Exit code to set build unstable:
2
Now things get a little tricky.
This operation has to
merge changes into two branches: the master and the development-branch.
Merging into the master is easy! There is just no way any conflicting changes could have gotten into the master-branch! So its save to enforce to always take changes from the hotfix-branch!
With the development-branch on the other hand, its not so easy!
The longer the hotfix-branch is open, the more likely it is, that there will be merge-conflicts - and we have to handle them!
The default-value of the MergeStrategy-parameter is
AUTO. With this, the gitflow-plugin tries to merge the branches without any special treatment.
If that fails, then its the turn of the developers to decide how to solve the merge-conflicts - after all, they've produced them in the first place.
To make things easier, they have 3 options:
- ignore the conflicting changes in the development-branch and just merge the changes from the hotfix-branch
- vice-versa: ignore the conflicting changes in the hotfix-branch and just keep the changes in the development-branch
- do not merge into development-branch at all and keep the hotfix-branch!
In the first two cases, you can just re-run the Job, with the MergeStrategy-parameter set to the corresponding option, and thats it.
In the last case ..well, you also re-run the Job, with the MergeStrategy-parameter set to the corresponding option - but one (or more) of the developers have to take care of merging the changes into the development-branch and deleting the hotfix-branch afterwards!
That's a little bit more work, as the developers have to respect the different versions in the pom.xml files (in the jenkins-job, the gitflow-maven-plugin will take care of this). But as mentioned before: they're responsible for the merge-conflicts they've introduced.
Version-Create-Release-Branch
Parameter:
Type:
Extensible Choice
Name:
ReleaseVersion
Groovy Script:
def p = "/path/to/fetch-git-version.sh".execute()
p.waitFor()
File versions = new File("/path/to/git-current-version.txt")
return versions.readLines()
fetch-git-version.sh:
#!/bin/bash
credentials=`cat ~/.bitbucket_user`
curl -u "$credentials" "https://yourgitrepo/projects/PRJ/repos/repo-name/raw/pom.xml?at=refs%2Fheads%2Fmaster" > /tmp/repo-pom.xml
grep -m 1 "" /tmp/repo-pom.xml | sed -e 's/.*version>\(.*\)<\/version>/\1/gi' > /path/to/git-current-version.txt
Parameter:
Type:
Text
Name:
DevelopmentVersion
Shell Build-Step:
echo "Checking target release-version...";
if [[ ! "${ReleaseVersion}" =~ ^[0-9]{2}\.[0-9]{1,2}\.[0-9](\.[0-9]+)?$ ]]; then
echo "Invalid Release-Version specified! Aborting!";
exit 1;
fi
echo "Enforcing SNAPSHOT for dev-version...";
if [[ ! "${DevelopmentVersion}" =~ ^.*-SNAPSHOT$ ]]; then
DevelopmentVersion="${DevelopmentVersion}-SNAPSHOT"
fi
echo "Checking target dev-version...";
if [[ ! "${DevelopmentVersion}" =~ ^[0-9]{2}\.[0-9]{1,2}\.[0-9](\.[0-9]+)?-SNAPSHOT$ ]]; then
echo "Invalid Development-Version specified! Aborting!";
exit 1;
fi
echo "Fetching repository...";
git clone ssh://USER@yourgitrepo:9999/prj/repo-name.git
cd repo-name
git branch -r | grep -v '\->' | grep -v 'master' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git pull --all
echo "Starting release-branch...";
mvn -B gitflow:release-start -DversionProcessAllModules=true -DpushRemote=true -DuseSnapshotInRelease=true -DallowSnapshots=true -DcommitDevelopmentVersionAtStart=true -DreleaseVersion="${ReleaseVersion}" -DdevelopmentVersion="${DevelopmentVersion}" -DversionDigitToIncrement=2
In our company the colleagues want high flexibility regarding the version-numbers.
But to make things a bit easier and give them some support, we use the extensible choice plugin, to show the current version.
I'm sure, you can do the same thing completely in groovy, without a separate shell-script - but I found this solution shorter, more easy and especially more quick to implement!
In the build-step, the important part is, to check and enforce SNAPSHOT-version for development-branch! You can not rely on you users to get this right! Really!
For the release-branch the gitflow-plugin will take care of this (via parameter
-DuseSnapshotInRelease=true)
Version-Finish-Release-Branch
Parameter:
Type:
Select
Name:
MergeStrategy
Values:
AUTO
HOTFIX
STAGING
MANUAL
Shell Build-Step:
echo "Fetching repository...";
git clone ssh://USER@yourgitrepo:9999/prj/repo-name.git
cd repo-name
git branch -r | grep -v '\->' | grep -v 'master' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git pull --all
echo "check for existing release-branch..."
amount=`git branch -r |grep -i "hcf-" | wc -l`
if [ $amount -eq 0 ]; then
echo "No existing release-branch found! Aborting...";
exit 2;
fi
skipMergeDevBranch="false"
keepReleaseBranch="false"
devBranchMergeOptions="";
if [ "${MergeStrategy}" == "HOTFIX" ]; then
devBranchMergeOptions="-Xtheirs";
elif [ "${MergeStrategy}" == "STAGING" ]; then
devBranchMergeOptions="-Xours";
elif [ "${MergeStrategy}" == "MANUAL" ]; then
skipMergeDevBranch="true";
keepReleaseBranch="true";
fi
echo "Finish release-branch...";
mvn -B gitflow:release-finish -DversionProcessAllModules=true -DpushRemote=true -DuseSnapshotInRelease=true -DskipTestProject=true -DallowSnapshots=true -DcommitDevelopmentVersionAtStart=true -DproductionBranchMergeOptions="-Xtheirs" -DdevBranchMergeOptions="${devBranchMergeOptions}" -DkeepBranch="${keepReleaseBranch}" -DskipMergeDevBranch="${skipMergeDevBranch}" -DversionDigitToIncrement=2
Much like the "
Version-Finish-Hotfix-Branch" - except that it'll check for existing release-branch and use the corresponding gitflow-plugin goal.
The concerns regarding merge-conflicts apply to this job as well.
Conclusion
With this Tools and Jenkins-Jobs at hand, you can leave release-management to a non-technical person in most cases. And even for the developers, things get a lot easier and more convenient.
And more important: your repository and releases will be in a consistent and reproducible state!
Any comments and improvements welcome!